昨天我們提到了Self-attention的input是什麽樣子,output應該又是什麽樣子。我們知道Self-attention是爲了解決比較複雜的input,比如說輸入的input的長度不是固定的,然後output有三種情況,輸出和輸入一樣多、輸出一個label、模型自己決定輸出多少個label。今天我們就來稍微介紹Self-attention在輸出和輸入一樣多的情況下,我們到底該怎麽做。
這種輸入跟輸出數目一樣多的狀況叫做Sequence Labeling(序列標註),需要為序列中的每個向量分配一個標籤。一個直觀但不完美的方法是,將每個向量單獨丟進全連接神經網絡(Fully-Connected Network),無視它們之間的順序,逐個處理。這樣,網絡會給出輸出,然後根據需求執行回歸或分類。然而,這種方法有明顯的缺陷。
假設我們要進行詞性標註,給網絡一個句子:「I saw a saw」。對於全連接層來說,兩個「saw」完全一樣,因為它們是同一個詞彙。這會導致網絡給出相同的輸出,而實際上,我們希望第一個「saw」是動詞,第二個是名詞。這種情境下,網絡無法區分它們,因為它缺少上下文的考慮。
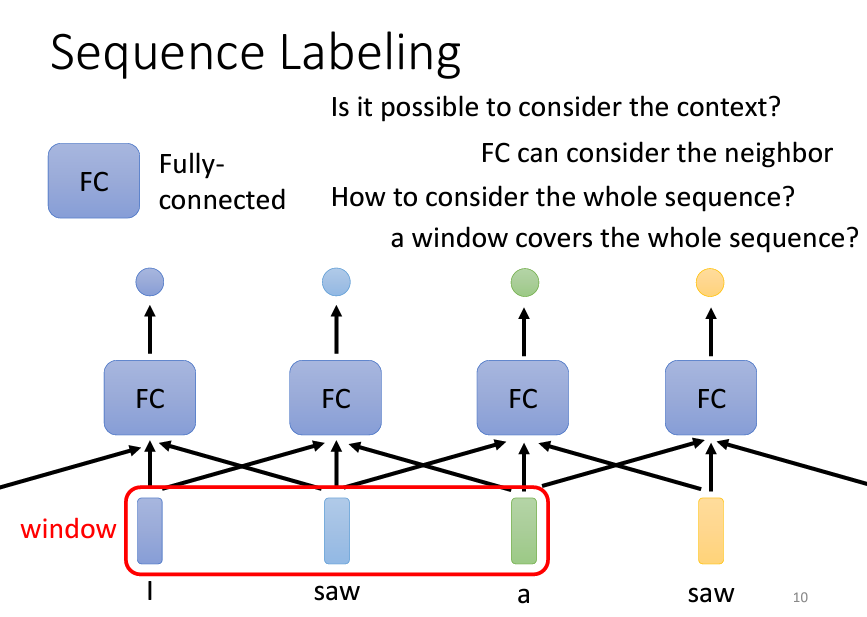
為了讓網絡考慮更多上下文資訊,可以將一個向量與其前後的向量一起輸入到全連接層中。在某些任務中,例如詞音標註(Phonetic Labeling),這種方法效果不錯。我們可以在網絡輸入時使用一個window「窗口」,例如考慮當前帧的前後5個帧(總共11個帧),這樣可以為網絡提供足夠的上下文,並獲得不錯的結果。
然而,這種基於窗口的方法也有其局限。如果任務需要考慮整個序列,而不僅僅是局部上下文,那麼增大窗口尺寸並不是理想解法。這會導致網絡需要更多的參數,增加運算量,並可能引發overfitting問題。
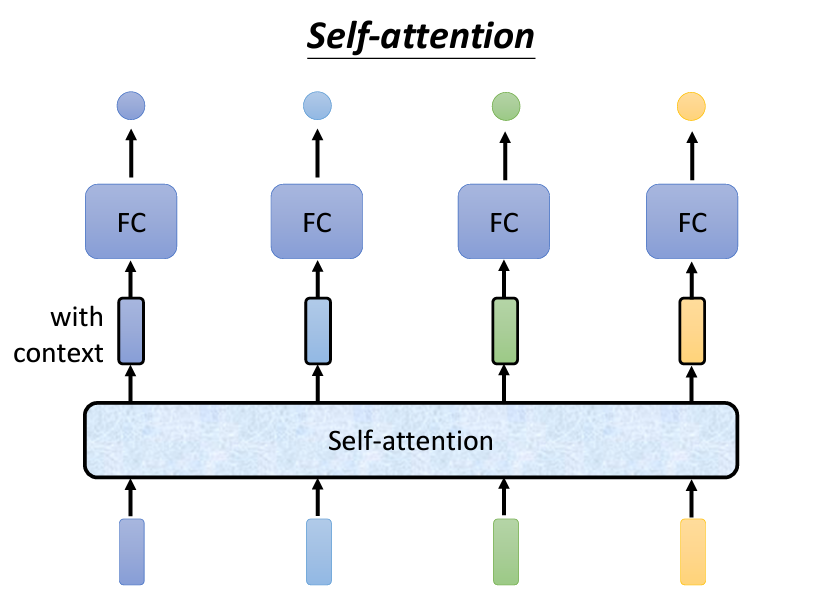
在處理整個input的資訊時,Self-Attention 是一個強大的技術。Self-Attention 能夠讀取整個序列,並為每個輸入向量生成相應的輸出。這些輸出向量是基於整個序列的信息,而不是單獨考慮某一部分。例如,當輸入4個向量時,Self-Attention 會輸出4個考慮整個序列後生成的向量。
這些經過 Self-Attention 的向量可以再丟入全連接層,讓網絡根據完整序列的信息,來判斷輸出的類別或數值。這樣,全連接層不再只考慮局部窗口的資訊,而是整個序列,從而生成更加準確的結果。
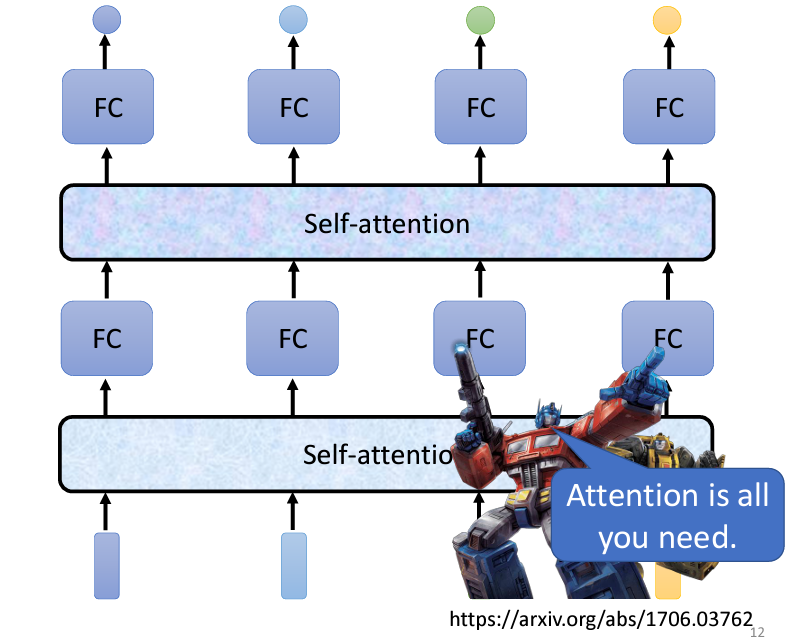
Self-Attention 也可以多次疊加使用。例如,Self-Attention 的輸出經過全連接層處理後,可以再一次進行 Self-Attention,並重複這個過程。這種交替使用 Self-Attention 和全連接層的方式,使得網絡能夠充分考慮整個序列的資訊。
Self-Attention 是 Transformer 架構中的核心模組,而 Transformer 是 Google 提出的深度學習模型,它的經典論文[Attention is All You Need]將這個技術推向了主流。
雖然 Self-Attention 最廣為人知的應用來自於[Attention is All You Need]這篇論文,但其實在更早的研究中也有提出類似的架構,只是名稱各異,例如 Self-Matching 等。然而,正是這篇論文讓 Self-Attention 模組得以廣泛應用和發展。
但是今天我們不會談論到這個 Transformer,我們只要知道它依賴於 Self-Attention 來處理序列資料,並已成為許多自然語言處理(NLP)任務中的標準方法就好了。
Self-Attention 的輸入是一串向量,這些向量可能是整個網絡的輸入,也可能是某個隱藏層的輸出。為此,我們用 a 表示輸入向量,以區分它們可能是前面處理過的結果。Self-Attention 的輸入是一排 a 向量,輸出則是一排 b 向量,其中每個 b 向量是基於整個 a 序列的資訊生成的。換句話說,每個輸出的 b 向量都考慮了整個序列的上下文。
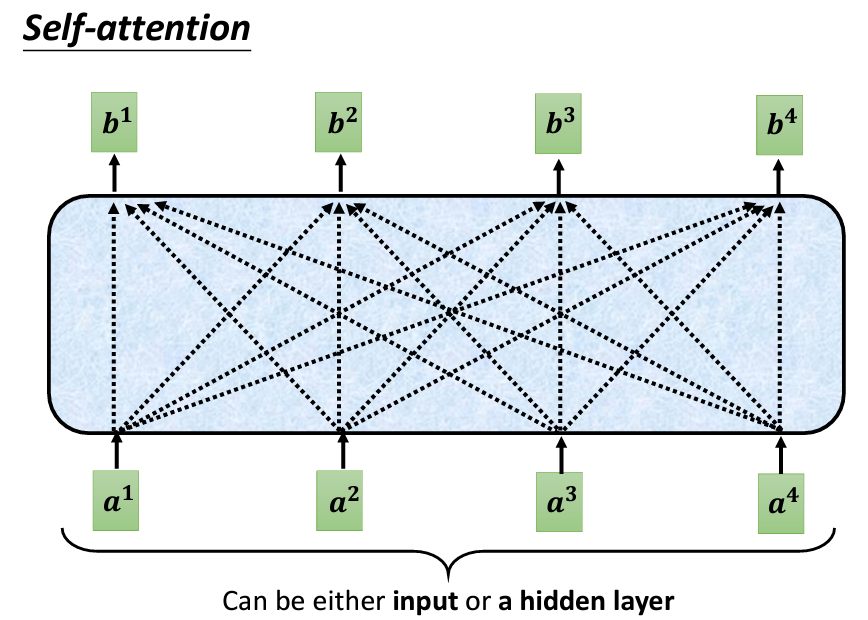
b 向量?要生成 b_1 向量,我們首先需要找到與 a_1 相關的其他向量。Self-Attention 的目的是考慮整個序列中的資訊,但不希望簡單地將所有資訊集中到一個窗口內。因此,Self-Attention 設計了一個機制,能夠自動找出與 a_1 判斷相關的其他向量。每個向量與 a_1 的關聯程度可以用一個數值 alpha 來表示。
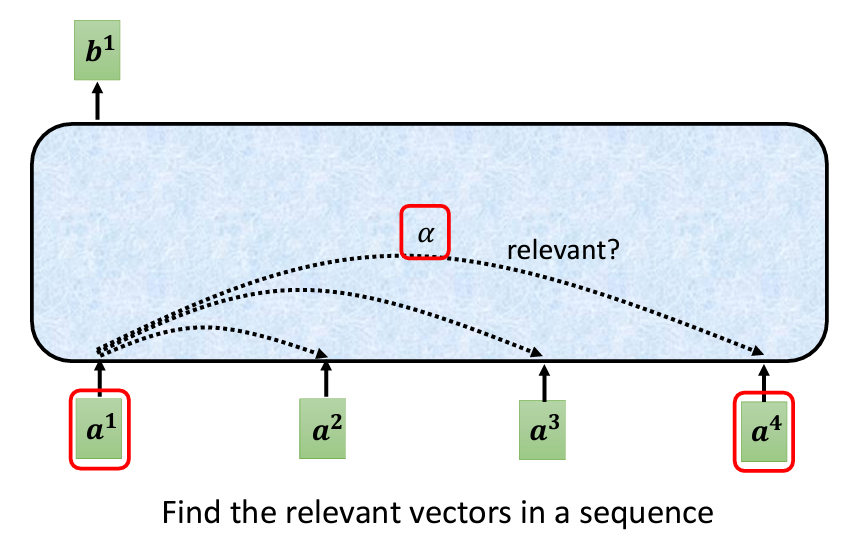
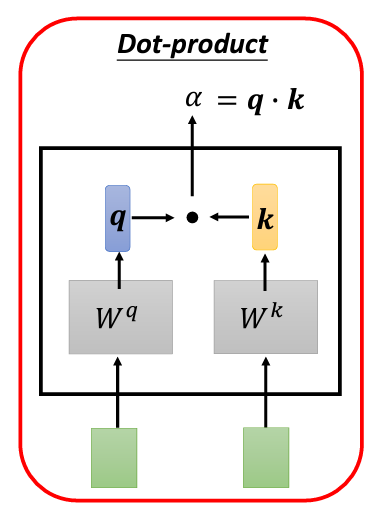
接下來的問題是:Self-Attention 如何自動計算兩個向量之間的關聯性,並生成 alpha?這裡需要使用一個 Attention 計算模組。這個模組會將兩個向量作為輸入,並輸出一個代表它們關聯性的 alpha 值。
alpha 的方法計算 alpha 的方式有多種,最常用的是點積(dot product)方法。具體來說,將輸入的兩個向量分別乘以兩個不同的矩陣 W_q 和 W_k,得到 q 和 k 向量。然後,對 q 和 k 進行點積,將每個元素相乘再相加,最終得到一個標量(scalar),這個標量就是 alpha 的值。
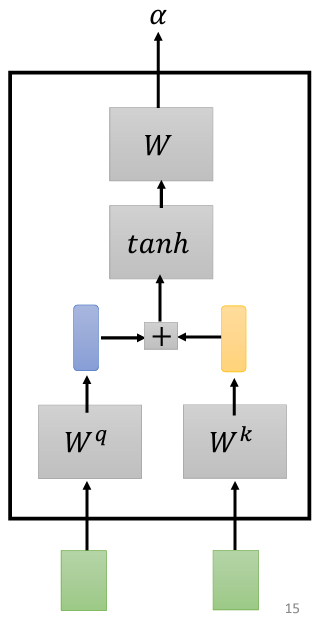
除了點積法,還有其他方法可以計算 alpha,例如加法式(Additive)方法。這種方法將 q 和 k 串接起來,通過激活函數,再經過一個變換來生成 alpha。雖然有很多不同的計算方法,但我們在這裡主要討論點積法,因為它是目前最常用的方法,也是 Transformer 中採用的方法。
明天的内容會是都是數學的原理,先給一個 Math Warning。
以上的内容來自於臺大教授李宏毅:鏈接,我只是把他的影片寫成了筆記。

